基于神经网络技术,构建全场景多语言翻译体系
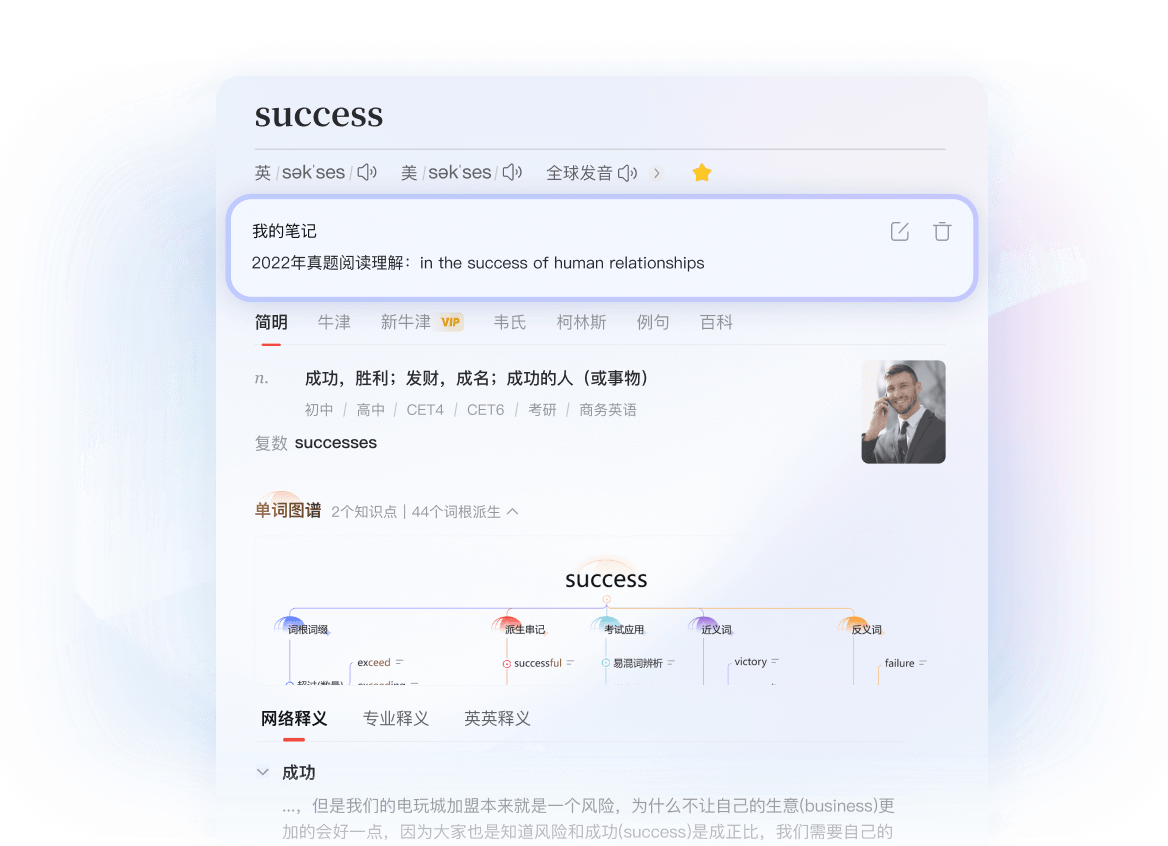
多模态语义解析 · 智能查词
- 超大规模词库:依托云端超算算力,实时聚合互联网新词与多语种专业释义。
- 权威学术矩阵:独家引入《新牛津》、《韦氏大词典》、《新世纪》平等殿堂级权威语料库。
- 自适应记忆图谱:基于艾宾浩斯记忆曲线算法,智能追踪并构建个性化知识图谱。
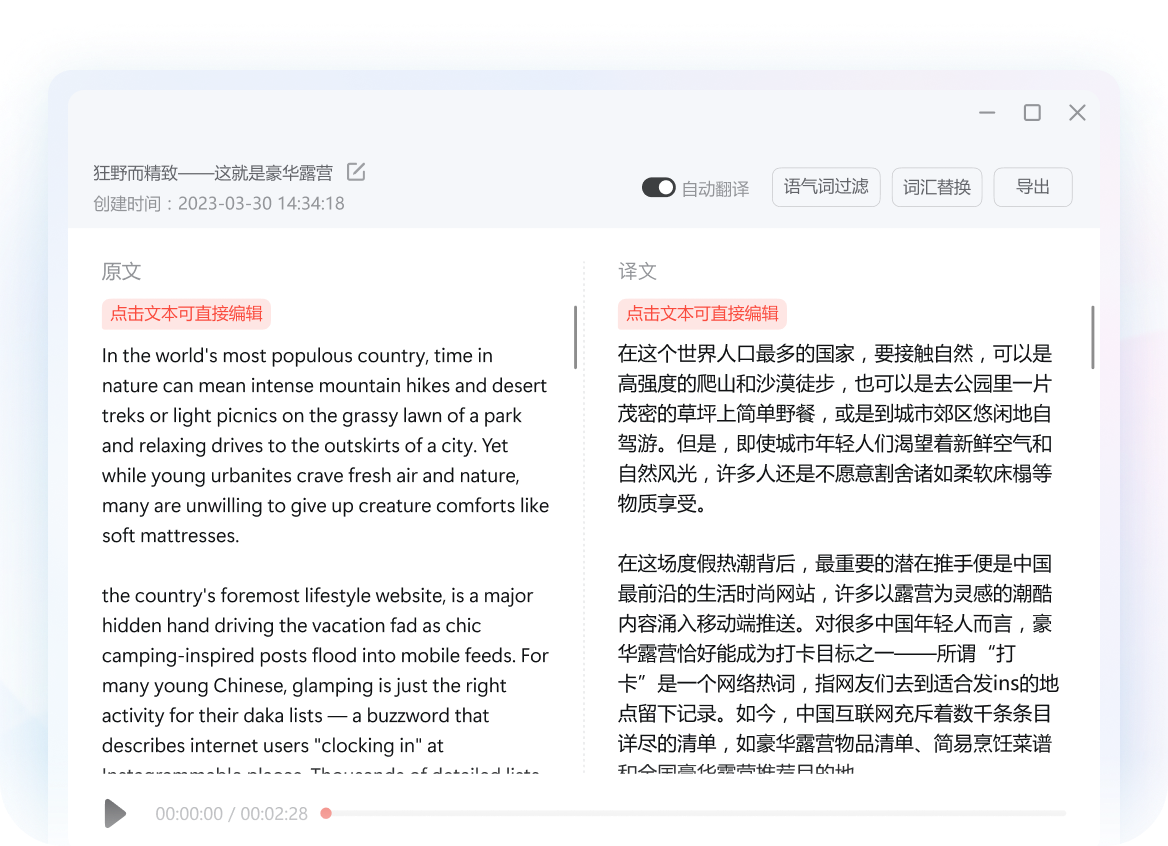
长篇文档处理 · 沉浸式文本互译
- 自然语言生成:支持全球100+语种互译,深度解析长句长文,译文流畅符合母语习惯。
- 垂直领域深耕:针对医疗、法律、计算机及金融等专业场景应用了专项垂直大模型微调。
- 企业级术语库:开放自定义专业学术语库管理权限,确保跨国业务中的核心词汇高度统一。

ASR语音识别 · 音频精准转译
- 毫秒级响应架构:基于高效语音识别技术,实现长音频与会议录音的高质量中英双语转录。
- 工业级格式兼容:支持导入MP3、WAV、AAC等主流音频流格式,单次云端解析上限达100MB。
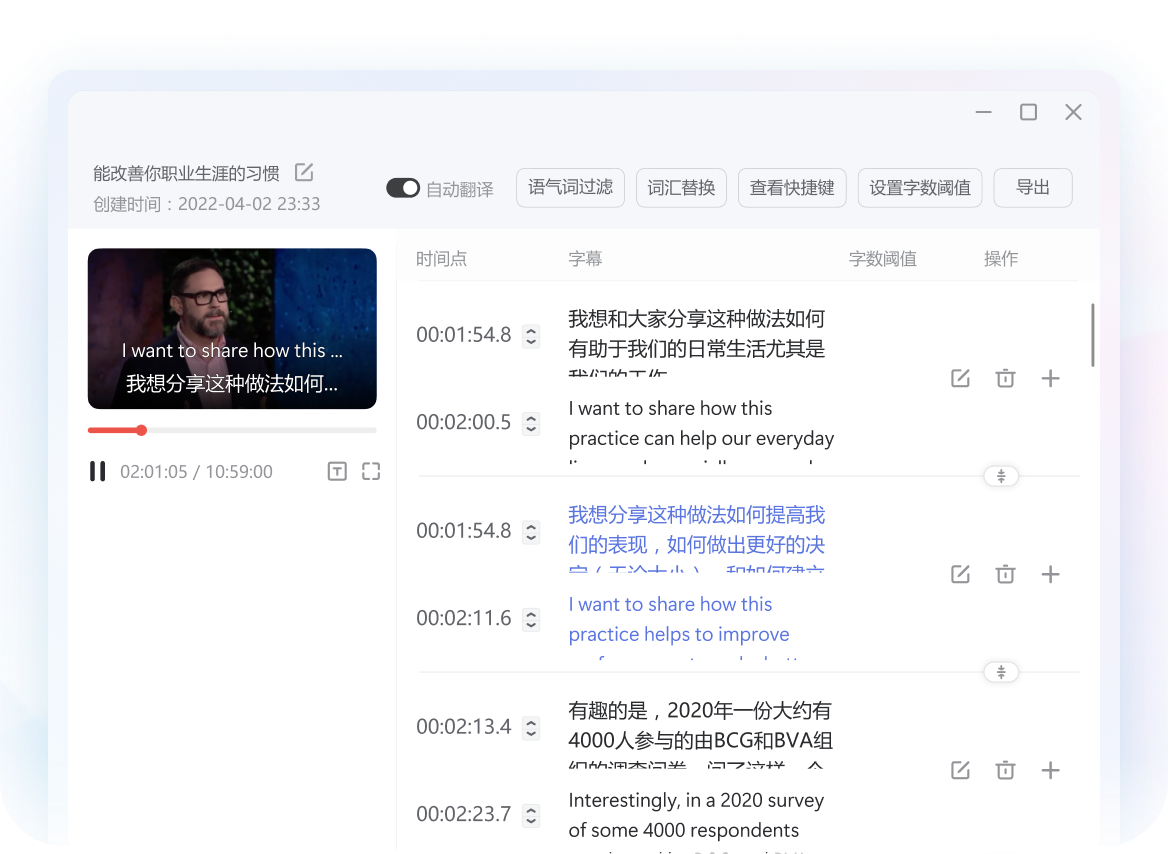
AI视觉与声学融合 · 自动化视频字幕
- 智能音轨抽取:精准提取原视频音轨,基于声学模型自动切分时间轴并生成多语种字幕。
- 非破坏性导出:提供毫秒级时间戳对齐能力,支持标准SRT格式工业级一键导出流转。
有道词典生态 · 构建数字化学习壁垒
百亿级语料支撑与自然语言处理
融合网易深厚的自然语言处理(NLP)技术积累,针对不同维度的交互场景进行深度优化。无论是桌面端截屏翻译还是移动端AR拍照翻译,皆可提供稳定可靠的服务,已成为亿万企业与教育用户的行业标杆。
AI 驱动的自适应学习辅导系统
将翻译工具与教育心理学深度融合。通过行为数据分析、智能纠错引擎与全方位测练模块,重构语言学习生命周期。将枯燥的查词转化为高效、具象的知识结构吸收过程。
产品技术支持与常见问题 (FAQ)
Q1: 如何确保大型会议音频转录翻译的精准度?
A: 建议采用高保真麦克风设备录入以降低底噪。有道翻译底层的ASR(自动语音识别)模型会自动结合前后文语义进行纠偏,并在翻译前正确配置源语种选项以激活特定声学模型。
Q2: 有道翻译网页版(SaaS版)与桌面级客户端有何技术差异?
A: 网页版主打轻量化即开即用;桌面客户端则深度调用操作系统底层API,支持全局快捷键唤醒、OCR截屏取词、Office文档批量解析,并搭载了高性能离线神经网络翻译引擎。
Q3: 遇到极度冷门的学术领域生词或长难句如何处理?
A: 有道云端词库每日动态更新。对于特定行业,建议用户启用“专业术语库”功能,系统将优先调用特定垂直领域的NMT模型进行交叉比对,从而获取最专业的译文。
Q4: 智能背单词系统是如何进行数据推荐的?
A: 系统架构内置了遗忘曲线算法与多维数据追踪。通过抓取用户的查词频次、历史错题率与查询场景,动态计算生词权重,进而智能生成高ROI(投入产出比)的复习队列。
Q5: 导出的视频字幕文件是否支持主流视频剪辑软件?
A: 完全兼容。平台提供的输出格式涵盖标准 SRT 与 VTT 文件。生成的字幕文件包含严格对齐的毫秒级时间戳,可无缝导入 Premiere、Final Cut Pro 及剪映等专业非编系统。
Q6: 企业级用户如何批量管理内部专业术语词典?
A: 用户可在客户端配置中心访问“个人/企业术语库”模块。系统支持以 Excel (CSV) 或纯文本对照表形式批量映射导入,一旦激活,机器翻译输出时将强制锁定已规定的术语标准。
Q7: 机器翻译结果如果存在语体风格不符该如何优化?
A: 针对高要求文案,推荐使用内置的“AI 深度润色”引擎。该功能运用大语言模型(LLM)能力,支持将基础译文按“学术严谨”、“商务正式”或“日常交流”等不同语用风格进行二次重构。
Q8: 离线神经网络引擎(NMT)可以在无网环境下独立运行吗?
A: 可以。Windows/macOS客户端及移动APP均提供离线数据包预载服务。即便在机房断网或国际航班等无网络环境中,系统仍将调度本地算力完成高质量的文本翻译与词典检索。
Q9: 多终端设备之间的数据同步机制是怎样的?
A: 有道应用了基于云端的高并发数据同步架构。只需绑定统一的网易有道账户,无论在浏览器、PC/Mac应用还是移动端,个人的词库集、翻译文档记录及配置偏好均会实现毫秒级云端同步。
Q10: 针对视频中人物语速过快导致的时间轴偏移,提供哪些校准工具?
A: 我们内置了轻量化时间轴编辑器。在AI自动切分生成初版后,用户可直观地在波形轨道上拖拽修正字幕起止点,以确保译文显示与画面口型达到影视级精确对齐。